

이 글은 2023-2 졸업 프로젝트 개발 일지를 기록하는 두번째 시리즈의 글입니다.
👉 이전 글 (데이터셋 생성부터 Colab으로 YOLOv5 학습까지) 보러가기
프로젝트에 대한 기본 소개를 먼저 한 후에
오늘의 주제인 '프로젝트에 GPT API 연동하여 서비스 구현하기'를 소개해보겠습니다!
⭐️
이 글은 처음으로 ChatGPT API를 프로젝트에 연동하려는 백엔드 개발자를 대상으로 작성했습니다.
GPT를 프로젝트에 연동하는 방법, 서비스 API에 적용하는 방법, 응답을 개선하는 방법에 대해 설명합니다.
🙌 Spring에 대한 기초적인 이해, CRUD에 대한 이해가 있는 분들이 읽기를 권장합니다!
혹시라도 CRUD에 대해 모르신다면, 아래 링크를 보고 오시는 것을 추천합니다.
↓
[웹개발의 봄, Spring] 2주차 개발일지(2) - JPA의 CRUD와 Repository
[웹개발의 봄, Spring] 2주차 개발일지(1) - RDBMS, H2, SQL 이번 포스팅에서 정리할 부분은 JPA와 Repository에 관한 내용이다. JPA 💡 JPA란? JPA는 SQL을 쓰지 않고 데이터를 생성, 조회, 수정, 삭제할 수 있도
mjmjmj98.tistory.com
0. 프로젝트 소개 🎨
프로젝트 명은 '외국인 관광객을 위한 한국미술 조각조각 뜯어보기 - 부분 해설 기반 미술관 도슨트 서비스'로,
외국인 관광객들에게 국내 미술관의 주요 작품들에 대한 해설을 '부분'으로 '인터렉티브'하게 제공하는 것이 목표입니다!
🖼
쉽게 예를 들어 유저 관점으로 설명드려보겠습니다.
국립중앙박물관에 방문한 관광객 A씨는 김홍도의 <서당>이라는 작품에 관심이 궁금합니다. 🤔
- A씨는 어플에 접속해 <서당>의 캡션을 찍어 그림을 인식📷 시킵니다.
- 어플은 <서당> 해설의 소제목들을 보여줍니다. (예. 1. 혼나는 아이 2. 혼내는 훈장님...) A씨는 훈장님이 가장 궁금해 2번을 선택했습니다.
- A씨가 2번 소제목에 해당하는 그림의 부분🧩 (즉, 훈장님)을 카메라로 찍으면 2번에 관한 해설이 제공됩니다!
- 이런 식으로 그림의 모든 소제목의 해설들을 Unlock🔓하면.. 그림에 대한 뱃지를 업적🏆으로 얻을 수 있게 되고, 나의 도감📜 에 저장됩니다.
- 이렇게, 서당이라는 그림을 퀘스트를 완수하듯 재미있게 감상한 A씨는 이제 다음 그림으로 넘어갑니다 :)
- 다음 그림은 <인왕제색도>입니다. A씨는 인왕제색도 그림에 그려진 '집'이 궁금합니다.
- A씨는 홈 화면에서 카메라를 켜 '집'을 촬영하고, 짧은 시간이 지난 후 '집'에 대한 해설을 보게 됩니다.
- 이와 같이 작품에서 궁금한 부분만 바로바로 촬영해서 해설을 빠르고 쉽게 얻을 수도 있습니다.
저희 서비스 플로우를 flowchart로 정리해보자면, 다음과 같습니다.

1️⃣ 주요 기능
1) OCR을 통해 작품 캡션 촬영만으로 작품 검색 🎨
직접 작품명을 정확하게 타이핑하거나 검색할 필요 없이 간단하게 사진 촬영만으로 원하는 작품의 해설을 감상할 수 있습니다.
2) YOLO를 이용한 작품 요소 인식 🔎
한 작품에서 주목하면 좋을 부분들을 표시해둔 뒤 사용자가 해당 부분을 찾으며 더 자세히 살펴보도록 유도합니다. 유저가 작품의 부분을 직접 촬영해 수집하는 인터렉션을 제공합니다!
3) 부분 해설 🧩
작품의 긴 해설을 여러 부분으로 나누어 소제목별로 해설을 제공합니다. 다국어 해설, 오디오 해설, 배속 기능도 제공합니다!
4) GPT로 궁금한 부분 해설 보기 🤔
한 작품에서 원하는 부분의 해설만 빠르게 볼 수 있습니다. 메인 화면에서 카메라를 켜 그림의 궁금한 부분을 찍으면 GPT를 통해 해당 부분의 해설을 바로 얻어볼 수 있습니다.
2️⃣ 서비스 아키텍처

주요 스택은 다음과 같습니다!
- Front-End: Flutter + React
- Back-End: Spring + AWS Services
👉 참고 사항으로 제 개발 환경을 말씀드리자면,
저는 intelliJ 에서 GPT API를 연동하여 Spring으로 API를 개발했습니다!
지금까지는 프로젝트 소개였고 이제 본격적으로 GPT 컨텐츠로 들어가봅시다.
이번 포스팅에서는
1) GPT API 연동하기
2) GPT 를 이용한 API 개발하기
3) GPT 성능 개선하기
를 해볼 것입니다!
쉽고 자세하게 알려드릴 예정이니 천천히 따라와주세요~!
자세하게 알려드릴 예정이니~ 충분히 할 수 있습니다. 🔥

1. GPT API란? 🤔
ChatGPT API란, OpenAI에서 만든 대화형 인공지능 모델인 ChatGPT를 API로 사용할 수 있는 API입니다.
이 API는 HTTP 프로토콜 기반 Rest API 형태로 되어 있어서 네트워크를 통해 request를 받고 response를 반환합니다.
개발자가 GPT 모델을 활용하여 다양한 자연어 처리 작업을 수행할 수 있게 해주는 프로그래밍 인터페이스를 제공합니다.
즉, 텍스트 생성, 질문 응답, 언어 번역, 자연어 이해 등 다양한 NLP(Natural Language Processing) 작업에 모델을 적용할 수 있습니다!
2. GPT API 초기 세팅하기 ⚙️
GPT API를 연동하기 위해서는 OpenAI의 service key를 발급받아야 합니다.
STEP1. 서비스 키 발급
먼저, 이 OpenAI 사이트에 접속해주세요.
👉 https://platform.openai.com/account/api-keys
사이트에 접속하면 다음과 같은 화면이 뜨는데 먼저 로그인을 해주셔야 합니다.
GPT에 요청이 한번씩 보내질 때마다 사용자 계정 사용량에 누적시키기 때문에 로그인이 필요합니다.
chatGPT를 한번이라도 쓰셨던 경험이 있으셨던 분이라면 계정이 있을 건데요, 해당 계정으로 로그인하시면 됩니다.
계정이 없으시다면 회원가입 후 로그인 진행해주세요!
로그인을 하고 링크에 다시 접속하면 아래와 같이 서비스 키를 발급할 수 있는 화면이 뜹니다.
[Create new secret key] 를 눌러 서비스 키를 생성해봅시다.
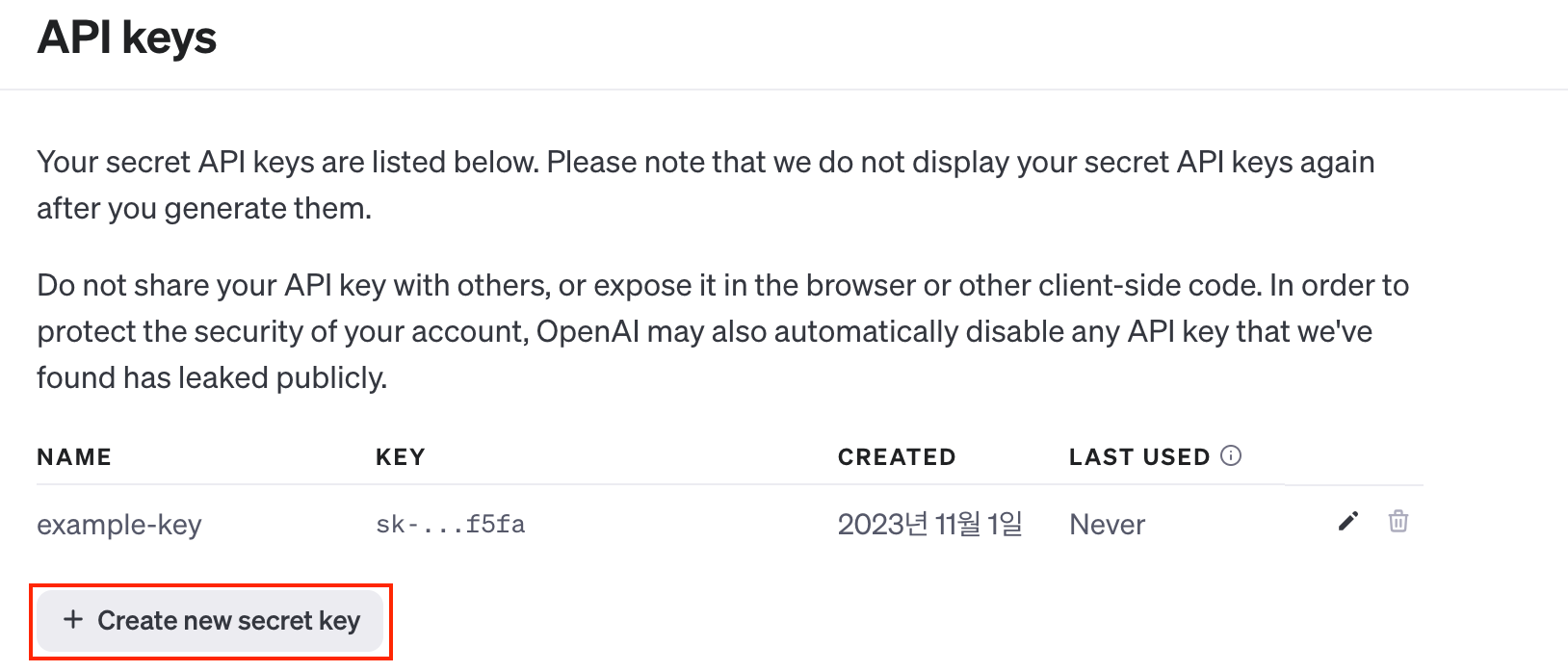
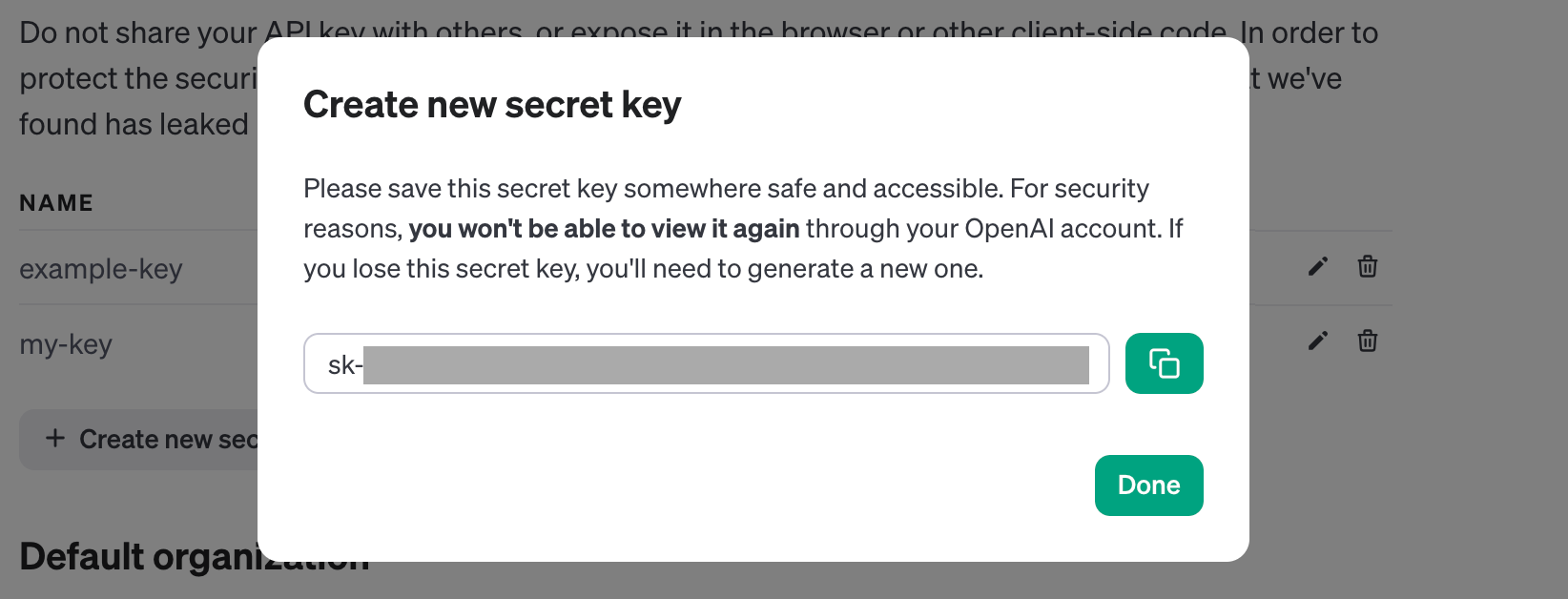
원하는 서비스키명(Name)을 입력하고 Next를 클릭하면 이 화면이 뜨는데요.
여기 나오는 긴 텍스트는 바로 api 사용을 위한 api-key 이니, 꼭 복사해서 보관해두셔야 합니다. 사용하시는 메모 어플 등에 꼭! 복사해두세요.
⭐️ 서비스 키는 보안을 위해 GitHub, 기술블로그 등 퍼블릭한 곳에 보관해두면 안됩니다. 유의하세요.
STEP2. 의존성 주입을 위한 라이브러리 추가
이제 프로젝트에 GPT를 사용하기 위한 의존성을 추가해주어야 합니다.
저는 Spring으로 개발을 하고 있기 때문에 build.gradle 파일에 의존성을 추가해주었습니다.
Spring Boot에 사용할 수 있는 괜찮은 라이브러리를 깃허브에서 발견해서 아래 라이브러리로 의존성을 주입했습니다!
해당 라이브러리를 통해 GPT를 Chat용으로 사용하거나 Image generation용으로도 사용할 수 있다고 합니다. Chat같은 경우에는 multi message까지 지원해서 대화의 히스토리를 이용할 수도 있습니다.
👇 라이브러리 내용 발췌
Chat
- You can chat with ChatGPT using many models. Also, multi message is supported, so you can take a series of messages (including the conversation history) as input , and get a response message.
Image generation
- Give a prompt and get generated image(s).
[build.gradle]
implementation 'io.github.flashvayne:chatgpt-spring-boot-starter:1.0.4'
👇 사용한 라이브러리
GitHub - flashvayne/chatgpt-spring-boot-starter: a chatgpt starter based on Openai Official Apis.
a chatgpt starter based on Openai Official Apis. Contribute to flashvayne/chatgpt-spring-boot-starter development by creating an account on GitHub.
github.com
STEP3. 환경변수 추가
설정파일에 gpt api key를 추가해주어야 합니다.
여기서 말하는 설정 파일은 프로젝트 내 파일 중 application.properties 나 application.yml을 뜻합니다!
본인 프로젝트에 맞는 파일에 키를 추가해주면 됩니다.
[application.yml]
chatgpt:
api-key: #your chatgpt-api-key
3. GPT로 API 개발하기 🖊️
이제 GPT를 사용할 수 있는 세팅은 마쳤습니다.
본격적으로 GPT를 활용해 API를 개발해볼까요?
저희가 생성할 파일과 디렉토리는 이렇게 되니 참고해주세요.
파일별 간단한 설명도 드릴게요.
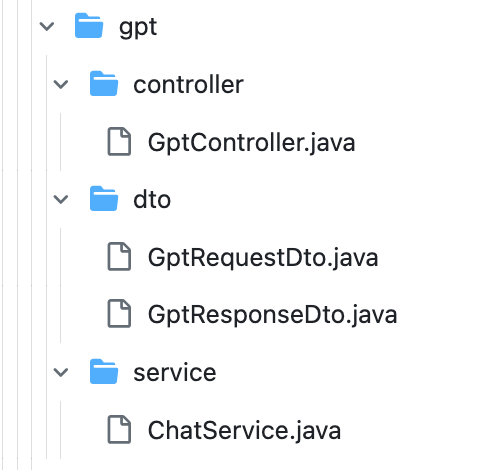
- GptController.java: 이 파일은 GPT와 관련된 HTTP 요청을 처리하는 Spring MVC 컨트롤러입니다.
- GptRequestDto.java: 이 파일은 GPT 관련 HTTP 요청에서 사용되는 데이터 전송 객체(DTO)입니다. 요청에 필요한 데이터를 캡슐화합니다.
- GptResponseDto.java: 이 파일은 GPT 관련 HTTP 응답에서 사용되는 데이터 전송 객체(DTO)입니다. 응답으로 전송할 데이터를 캡슐화합니다.
- ChatService.java: 이 파일은 GPT와 관련된 비즈니스 로직 및 데이터 처리 서비스를 제공하는 Spring 서비스 클래스입니다. GPT 모델과 상호 작용하며 필요한 데이터를 처리합니다.
STEP1. 컨트롤러, DTO 작성
API를 개발하기 위해선 먼저 컨트롤러(Controller) 파일과 DTO 파일을 작성해주어야 하는데요.
본인 프로젝트 API 시트에 맞게 작성하시면 됩니다 :)
제 API 시트를 보여드릴게요.


이제 API 시트에 맞게 파일을 작성해볼까요?
[GptController.java]
@RequestMapping("/app/gpt")
public class GptController {
private final ChatService chatService;
@PostMapping("/elementsinfo")
public ResponseEntity<GptResponseDto> getElementInfo(@RequestBody GptRequestDto requestDto) {
GptResponseDto response = chatService.getElementInfo(requestDto.getName());
return ResponseEntity.ok(response);
}
}
저는 API의 URI는 app/gpt/elementsinfo로 설정하였고 Post 방식으로 매핑하였습니다.
요청을 위한 RequestBody를 담을 Dto 파일은 'GptRequestDto'이고, 응답을 받아올 Dto 파일은 'GptResponseDto'로 설정해두었습니다.
그리고 실제 로직이 돌아갈 서비스 파일 'chatService' 에서의 메서드는 'getElementInfo'입니다.
본인의 프로젝트에 맞게 URI를 작성하시고 메서드를 매핑하시면 됩니다!
[GptRequest.java]
public class GptRequestDto {
private String name;
public GptRequestDto() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public GptRequestDto(String name) {
this.name = name;
}
}
API에 요청을 보내는 형식의 파일입니다!
저는 작품의 부분명(ex. <서당>의 '훈장님') 을 name으로 request body에 담아 request할 것이기에 위와 같이 작성했습니다.
각자 프로젝트에 맞게 어떤 요청을 보낼지 생각한 후, dto를 작성하면 됩니다!
[GptResponse.java]
@Getter
@NoArgsConstructor
public class GptResponseDto {
private Long relicId;
private String relicName;
private String ElementImage;
private String ElementName;
private String ElementDescription;
public GptResponseDto(Long relicId, String relicName, String ElementImage, String ElementName, String ElementDescription) {
this.relicId = relicId;
this.relicName = relicName;
this.ElementImage = ElementImage;
this.ElementName = ElementName;
this.ElementDescription = ElementDescription;
}
public Long getRelicId() {
return relicId;
}
public String getRelicName() {
return relicName;
}
public String getElementImage() {
return ElementImage;
}
public String getElementName() {
return ElementName;
}
public String getElementDescription() {
return ElementDescription;
}
}
클라이언트에 API의 응답으로 줄 형식의 지정한 파일입니다!
저는 작품명, 작품id, 부분명, 부분이미지, 부분의 해설을 응답으로 보내주도록 설정했습니다.
여기서 '부분의 해설(=ElementDescription)' <- 이 부분에 GPT를 통해 받은 응답을 넣어줄 예정입니다!!
Request Dto와 Response Dto는 본인 프로젝트 API 시트에 맞게 작성하시면 됩니다 :)
STEP2. 서비스 파일 작성
이제 GPT에 요청을 하고, 응답을 받아오기 위한 service 파일을 작성해보겠습니다!
사실 서비스 파일에 데이터베이스에서 작품을 꺼내오고 국문명을 찾아오는 등의 로직이 있는데, 이는 제 프로젝트에서만 사용되는 부수적인 로직이기에
GPT에 요청을 보내는 메서드만 설명드리겠습니다!
이것만 하셔도 문제 없습니다:)
[chatService.java]
public GptResponseDto generateDescription(String nameKr, String relicDescription) {
String prompt = "작품 전체해설에서 " + nameKr + " 정보 찾아줘."
+ "전체해설:\n" + relicDescription;
String elementDescription = chatgptService.sendMessage(prompt);
// 작품 정보 불러오기
Element element = elementRepository.findByNameKr(nameKr);
String elementImage = element.getImage();
Relic relic = element.getPart().getRelic();
Long relicId = relic.getId();
String relicName = relic.getNameEn();
// 응답 객체 반환
return new GptResponseDto(relicId, relicName, elementImage, nameKr, elementDescription);
}
서비스 파일에서 GPT에 질문을 던져주는 메서드는 generateDescription입니다.
이 메서드 내에서 프롬포트로 GPT에 질문을 하는 코드는 바로 이 부분입니다.
String prompt = "작품 전체해설에서 " + nameKr + " 정보 찾아줘." + "전체해설:\n" + relicDescription;
String elementDescription = chatgptService.sendMessage(prompt);
1) String으로 선언된 prompt에 gpt에 할 질문을 넣어줍니다.
2) sendMessage라는 메서드에 prompt를 넣어 gpt를 실행합니다.
3) gpt로 부터 받은 응답을 elementDescription에 저장합니다.
4) 받은 elementDescription을 response Dto에 넣어서 응답 객체로 반환해주도록 합니다.
STEP3. API 테스트 해보기
이제 API 작성을 마쳤으니 API 테스트를 해 볼 차례입니다.
Postman이나 Swagger 등 편한 방법으로 API 테스트를 하시면 됩니다.
저는 Postman을 통해 API를 테스트해보겠습니다.
포스트맨은 API를 빠르고 쉽게 테스트해볼 수 있는 웹 플랫폼입니다.
혹시나 포스트맨을 처음 써보시는 분들을 위해 짧게 소개하겠습니다.
👇 아래 링크로 접속해주세요
Postman API Platform | Sign Up for Free
Postman is an API platform for building and using APIs. Postman simplifies each step of the API lifecycle and streamlines collaboration so you can create better APIs—faster.
www.postman.com

로그인 후 [+] 버튼을 클릭 후 Collection을 생성합니다.
본인의 프로젝트명으로 이름을 설정해놓으면 편하겠죠?
[add request]를 눌러 이제 GET/POST/UPDATE 등 HTTP 메서드로 API를 테스트해보면 됩니다!
단언컨데 한번에 원하는 답변이 나오는 분은 없을 겁니다.

제 API 테스트와 함께 단계별로 트러블슈팅해볼거니 걱정말고 차근차근 따라와주세요 ~:)
위에서 짠 코드 그 상태로 첫 실행을 해보겠습니다.
이 시도에서 발생한 첫번째 문제는 바로 아래와 같습니다.
문제상황: GPT로부터 받은 응답이 담겨오지 않음.
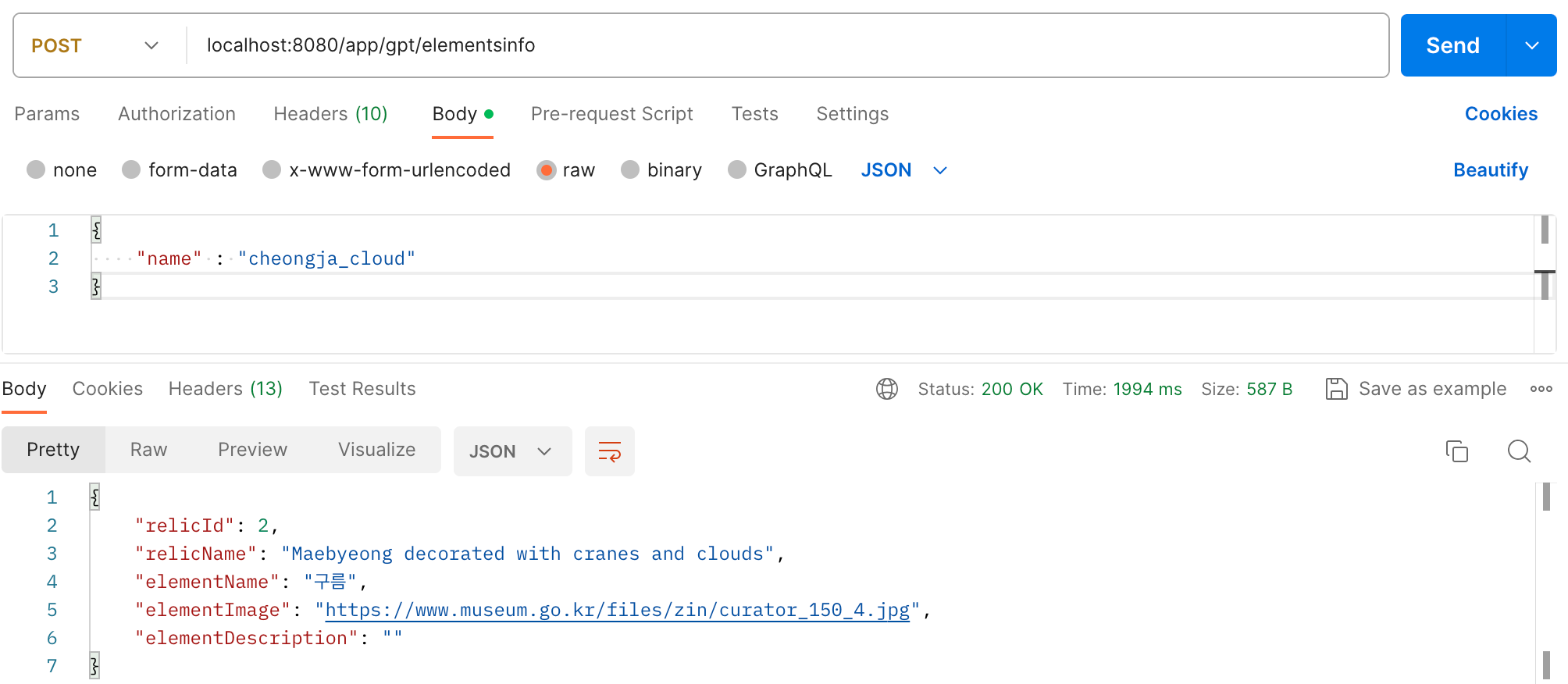
GPT로부터 받은 응답인 elementDescription에 아무것도 들어와있지 않네요.
이 문제를 해결하려면,
해결방법 STEP1. 로그를 찍어서 일단 GPT에 요청이 잘 보내졌는지부터 파헤쳐보아야 합니다.
일단 제 프롬포트부터 말씀드리자면 작품 전체 해설을 주면서 작품에서 어느 한 부분에 대한 정보를 찾아달라고 요청하고 있습니다.
[프롬포트]
작품 전체해설에서 구름 정보 찾아줘.
전체해설:
천년의 색을 간직한 고려청자 속에도 고려인의 마음을 담은 구름이 있습니다. 색과 무늬를 보면 이 항아리는 12세기 최전성기 고려청자의 비색을 품고 있으며, 다양한 무늬가 장식되어 있습니다. 뚜껑에는 꼭지를 중심에 두고 사방으로 마치 영지뭉치 같은 구름을 바람에 몰려다니듯 생기 있게 구불구불한 음각선으로 새겼습니다. 몸체 입구에는 큰 여의두문 띠를, 굽도리에는 뇌문 띠를 둘러 상감하였습니다. 몸체에 상감한 학은 귀와 귀 사이에 한 마리씩 총 4마리가 구름 사이를 노닐고 있습니다. 위를 올려다보는 학, 그에 화답하듯 아래를 바라보는 학, 옆을 나는 학 등 어느 하나 같은 모습이 없습니다. 여기에 학의 부리와 눈, 날리는 머리 깃과 꼬리 깃털, 다리를 흑상감으로 장식하여 생동감을 더합니다. 그런데 학 사이사이 상감된 구름무늬는 모양이 예사롭지 않습니다. 영지버섯 같은 구름이 꼬리가 세 갈래로 갈라지면서 길게 내려와 갈필로 그려낸 회화작품 같습니다. 이와 같이 고려청자에는 구름과 학을 함께 장식한 경우가 많습니다.
고려청자 속 구름무늬는 음각, 양각, 백화 등 다양한 기법으로 장식되었지만 상감기법을 가장 많이 사용하였습니다. 구름의 모양은 구름의 앞, 머리 모양에 따라 영지형, 적운형, 우점형으로 구분할 수 있습니다. 영지형 구름은 ‘청자 상감 구름 학무늬 매병’과 같이 옛 그림 속 고승의 지팡이 머리 혹은 영지버섯을 닮았습니다. 또한 구름 꼬리가 구불구불하고 긴 점이 특징입니다. 적운형 구름은 뭉게구름이 변형된 모양으로 구름 머리가 작고 꼬리가 짧습니다. 영지형 구름이 단순해진 모양입니다. 우점형 구름은 점점으로 흩어진 구름을 표현한 것입니다. 스프링처럼 꼬이거나 비가 내리듯 짧은 선으로 표현하였습니다.
로그를 확인해볼까요?
디폴트 모델인 text-davinci-003에 설정해놨던 prompt로 요청이 성공적으로 보내진 것을 확인할 수 있습니다.
max token은 디폴트는 500개로 되어있습니다.
[로그]
2023-11-14T00:27:12.253+09:00 INFO 76886 --- [nio-8080-exec-1] i.g.f.c.s.impl.DefaultChatgptService : request url:
https://api.openai.com/v1/completions,
httpEntity: <ChatRequest(model=text-davinci-003, prompt=작품 전체해설에서 구름 정보 찾아줘.전체해설:
천년의 색을 간직한 고려청자 속에도 고려인의 마음을 담은 구름이 있습니다. 색과 무늬를 보면 이 항아리는 12세기 최전성기 고려청자의 비색을 품고 있으며, 다양한 무늬가 장식되어 있습니다. 뚜껑에는 꼭지를 중심에 두고 사방으로 마치 영지뭉치 같은 구름을 바람에 몰려다니듯 생기 있게 구불구불한 음각선으로 새겼습니다. 몸체 입구에는 큰 여의두문 띠를, 굽도리에는 뇌문 띠를 둘러 상감하였습니다. 몸체에 상감한 학은 귀와 귀 사이에 한 마리씩 총 4마리가 구름 사이를 노닐고 있습니다. 위를 올려다보는 학, 그에 화답하듯 아래를 바라보는 학, 옆을 나는 학 등 어느 하나 같은 모습이 없습니다. 여기에 학의 부리와 눈, 날리는 머리 깃과 꼬리 깃털, 다리를 흑상감으로 장식하여 생동감을 더합니다. 그런데 학 사이사이 상감된 구름무늬는 모양이 예사롭지 않습니다. 영지버섯 같은 구름이 꼬리가 세 갈래로 갈라지면서 길게 내려와 갈필로 그려낸 회화작품 같습니다. 이와 같이 고려청자에는 구름과 학을 함께 장식한 경우가 많습니다.
고려청자 속 구름무늬는 음각, 양각, 백화 등 다양한 기법으로 장식되었지만 상감기법을 가장 많이 사용하였습니다. 구름의 모양은 구름의 앞, 머리 모양에 따라 영지형, 적운형, 우점형으로 구분할 수 있습니다. 영지형 구름은 ‘청자 상감 구름 학무늬 매병’과 같이 옛 그림 속 고승의 지팡이 머리 혹은 영지버섯을 닮았습니다. 또한 구름 꼬리가 구불구불하고 긴 점이 특징입니다. 적운형 구름은 뭉게구름이 변형된 모양으로 구름 머리가 작고 꼬리가 짧습니다. 영지형 구름이 단순해진 모양입니다. 우점형 구름은 점점으로 흩어진 구름을 표현한 것입니다. 스프링처럼 꼬이거나 비가 내리듯 짧은 선으로 표현하였습니다.
, maxTokens=500, temperature=1.0, topP=1.0, suffix=null, n=null, stream=null, logprobs=null, echo=null, stop=null, presencePenalty=null, frequencyPenalty=null, bestOf=null, logitBias=null, user=null),[Content-Type:"application/json;charset=UTF-8", Authorization:"Bearer"]>
요청도 잘 보내졌는데 대체 뭐가 문제일까요?
요청을 보낸 이후인, 로그의 다음줄을 읽어보겠습니다.
2023-11-14T00:27:13.582+09:00 INFO 76886 --- [nio-8080-exec-1] i.g.f.c.s.impl.DefaultChatgptService : response: <200 OK OK,ChatResponse(id=cmpl-, object=text_completion, created=+4656108-08-23, model=text-davinci-003, choices=[Choice(text=, index=0, logprobs=null, finishReason=stop)], usage=Usage(promptTokens=1888, completionTokens=null, totalTokens=1888)),[Date:"Mon, 13 Nov 2023 15:27:13 GMT", Content-Type:"application/json", Content-Length:"498", Connection:"keep-alive", access-control-allow-origin:"*", Cache-Control:"no-cache, must-revalidate", openai-model:"text-davinci-003", openai-organization:.............(생략)]>
response도 200으로 성공적으로 왔는데, Choice(text= 이 부분에 아무것도 담겨있지 않네요.
원래는 text="Gpt를 통해 받은 해설" 이런식으로 응답이 들어와있어야 합니다.
뭐가 문제일까?하고 다음줄을 읽어보니.. promptTokens=1888, completionTokens=null, totalTokens=188
토큰이 문제였네요!
무슨 소리냐구요?
바로 위에 있는 상자에서 요청시 로그를 분석해봤습니다. 이때 max token은 디폴트는 500개로 되어있습니다. 그런데, 응답 로그를 보면 프롬포트 로그가 1888입니다.
👉 max token수가 프롬포트에 필요한 토큰 수보다 훨씬 적으니 응답을 받아올 수 없는 거죠!
해결방법 STEP2. max token수를 늘려줘야 합니다.
gpt로부터 정상적으로 응답을 받아오려면 Max token 수를 늘려야겠죠?
max token 수는 서비스 키를 정의했던 것과 같이 환경파일에 정의하면 됩니다.
서비스 키는 chatgpt.api-key 로 정의했다면 max token 수는 chatgpt.max-tokens 로 정의하면 됩니다.
[application.properties]
# OpenAI configuration
chatgpt.api-key=${GPT_KEY}
chatgpt.max-tokens: 2200저는 max token수를 2200으로 설정해봤습니다.
이제 API를 재실행해볼까요?

API가 다음과 같이 GPT의 응답을 잘 담아오는 것을 볼 수 있습니다.
GPT로 응답 받아오기 성공!
4. GPT 응답 개선 작업하기 🌳
2번에서 끝낼 수 없는 이유가 있습니다.
2번에서 gpt로부터 받은 답변에 만족하시는 분이라면 2번에서 완료하셔도 됩니다.
하지만 프로젝트에 GPT를 연동하는 이유는 무엇인가요? 바로 빠른 시간 안에 "좋은" 답변을 얻기 위해서이죠.
다시 한번 아까 API로 받아오기 성공한 응답을 봐볼까요?
문제상황: GPT로부터 받은 응답이 문맥과 프롬포트와 전혀 맞지 않음.


저는 분명.. 작품 전체해설을 주고 여기에서 구름 정보를 찾아달라 했는데 문맥과 전혀 맞지 않은 응답을 내뱉네요..
해결방법: GPT model 을 프로젝트에 맞는 모델로 교체해봅시다.
STEP 1. GPT model 에 대해 알아봅니다.
GPT model에는 다양한 것들이 있습니다.
모델에 대한 소개를 읽어보고 여러분의 서비스에 맞는 것으로 변경하시면 됩니다.
어떤 모델이 있는지 보고 선택기준을 통해 적합한 모델을 골라봅시다.
OpenAI Platform
Explore developer resources, tutorials, API docs, and dynamic examples to get the most out of OpenAI's platform.
platform.openai.com
[선택기준 1] GPT-4 vs GPT-3.5선택하기
GPT-4 and GPT-4 Turbo
가장 최신인 GPT4는 이미지와 텍스트를 모두 입력받을 수 있고 GPT3보다 일반 지식과 고급 추론 부분에서 성능이 훨씬 뛰어나다고 합니다!
| gpt-4-1106-preview | GPT-4 Turbo
New
The latest GPT-4 model with improved instruction following, JSON mode, reproducible outputs, parallel function calling, and more. Returns a maximum of 4,096 output tokens. This preview model is not yet suited for production traffic. Learn more. |
128,000 tokens | Up to Apr 2023 |
| gpt-4-vision-preview | GPT-4 Turbo with vision
New
Ability to understand images, in addition to all other GPT-4 Turbo capabilties. Returns a maximum of 4,096 output tokens. This is a preview model version and not suited yet for production traffic. Learn more. |
128,000 tokens | Up to Apr 2023 |
| gpt-4 | Currently points to gpt-4-0613. See continuous model upgrades. | 8,192 tokens | Up to Sep 2021 |
For many basic tasks, the difference between GPT-4 and GPT-3.5 models is not significant.
공식 문서에도 많은 기본 작업의 경우 GPT-4와 GPT-3.5 모델의 차이는 크게 있지 않다고 말하니 굳이 gpt-4를 쓰진 않으려고 합니다!
GPT-3.5
가장 보편적인 모델인 3.5입니다.
| gpt-3.5-turbo-1106 | Updated GPT 3.5 Turbo
New
The latest GPT-3.5 Turbo model with improved instruction following, JSON mode, reproducible outputs, parallel function calling, and more. Returns a maximum of 4,096 output tokens. Learn more. |
16,385 tokens | Up to Sep 2021 |
| gpt-3.5-turbo | Currently points to gpt-3.5-turbo-0613. Will point to gpt-3.5-turbo-1106 starting Dec 11, 2023. See continuous model upgrades. | 4,096 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-16k | Currently points to gpt-3.5-turbo-0613. Will point to gpt-3.5-turbo-1106 starting Dec 11, 2023. See continuous model upgrades. | 16,385 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-instruct | Similar capabilities as text-davinci-003 but compatible with legacy Completions endpoint and not Chat Completions. | 4,096 tokens | Up to Sep 2021 |
| text-davinci-003 Legacy
|
Can do language tasks with better quality and consistency than the curie, babbage, or ada models. Will be deprecated on Jan 4th 2024. | 4,096 tokens | Up to Jun 2021 |
보통 chatGPT api로 gpt3.5-turbo 모델을 사용하지만,
저처럼 챗봇이 아닌 다른 목적으로 사용하는 경우 다른 모델을 선택해도 괜찮습니다!
[선택기준2] Completion vs ChatCompletion 중 선택하기
Completion vs ChatCompletion
GPT API는 크게 두가지로 나뉘어져있는데, Completion과 ChatCompletion입니다.
➤ 컴플리션은 단순 요청에 대한 대답을 주는 기능으로써, 사용이 간편합니다. 단점으로는 GPT가 이전 내용을 기억하지 못하기 때문에, 챗 GPT와 처음 대화한 기준의 답변만 받습니다.
➤ 챗 컴플리션은 GPT와 채팅하듯이 GPT가 기억할 내용을 미리 보내서 원하는 답변을 받을 수 있습니다.
( 예를 들어서, 어떤 개발자 분은 이력서 검토용 서비스를 만들기 위해 GPT에게 적절한 프롬프트를 학습시킨 뒤, 사용자의 요청을 보낼 생각이기 때문에 챗 컴플리션을 사용하셨다고 합니다.)
저는 그림의 부분에 대한 해설을 요청하기 위해 GPT를 사용하는데 그림마다 해설이 다르고 굳이 히스토리를 기억할 필요가 없어 Completion을 선택했습니다!
본인의 프로젝트에 맞는 것으로 택해주세요 😄
STEP 2. GPT model 을 직접 테스트해보고 파라미터를 조정해봅시다.
이제 후보들이 몇개 추려졌다면,
여러 GPT 모델을 OpenAPI Playground에서 직접 테스트해볼 수 있습니다.
↓↓
OpenAI Platform
Explore developer resources, tutorials, API docs, and dynamic examples to get the most out of OpenAI's platform.
platform.openai.com
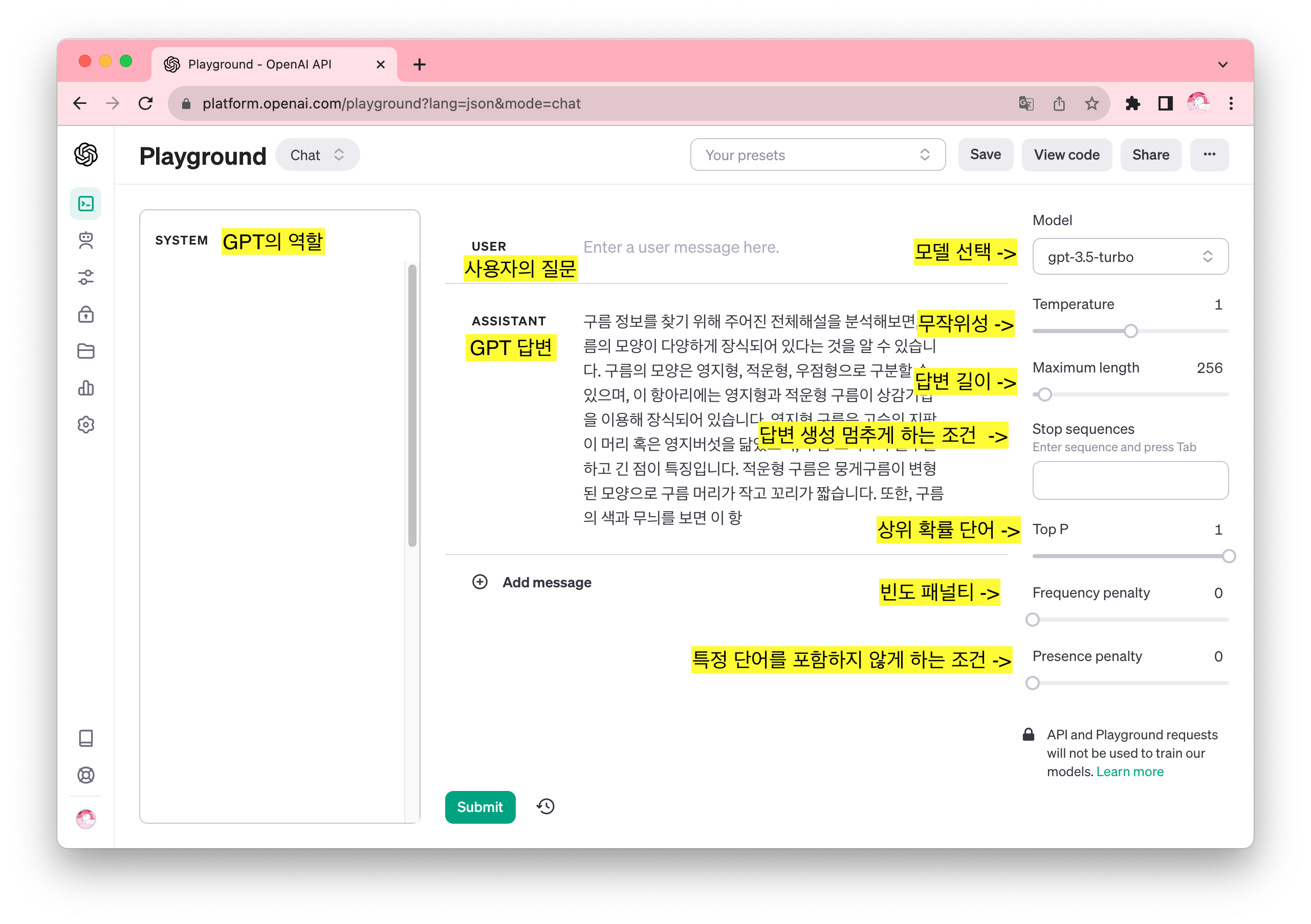
⭐️ 모델의 parameter들을 조절해보며 가장 적절한 모델과 parameter들을 맞춰보는 겁니다! ⭐️
각 항목별로 설명을 드리자면,
- SYSTEM : 챗GPT의 역할을 정해주는 항목. 어떤 목적으로 API를 이용하려고 하는지에 따라 역할을 부여해주시면 됩니다.
⭐️ 보통은 상황을 설정할 때 사용합니다.
예시- Act as a ___ , 너는 변호사 로봇이다와 같이 역할을 부여할 때 사용됩니다.
- USER & ASSISTANT : 사용자의 질문과 챗GPT의 답변 창입니다.
- Model : 언어 모델을 선택합니다.
- Temperature : 챗GPT 답변의 다양성을 나타냅니다. 같은 질문을 했을 때 값이 1에 가까우면 같은 답변을 제공하고, 0에 가까이하면 다른 답변을 제공합니다. 디폴트 값은 0.7입니다.
- Maximum Length : 챗GPT 답변의 최대 길이
- Stop Sequences : 사용자가 원할 경우 특정 토큰을 기준으로 해서 답변이 생성되는 것을 중지합니다. 답변 생성을 멈추게 할 수 있는 조건을 정의하여 불필요한 답변 생성을 방지하고 토큰 소모를 줄일 수 있도록 합니다.
- Top P : 다음 단어를 예측할 때 사용되는 하나의 매개변수입니다. 0부터 1까지의 값을 정의할 수 있고, 만약에 값을 0.2로 설정한다면 누적 분포 20%에 해당하는 단어들을 선택하여 문장을 구성하게 됩니다.
- Frequency Penalty : 반복되는 텍스트를 생성하는 것이 아닌 다양한 답변을 생성하도록 하는 조건입니다.
- Presence Penalty : 특정 단어를 포함시키지 않게 하는 조건입니다. 단어마다 점수를 매겨 작동하는 방식입니다.
여기서 테스트로 돌려보며 정한 모델과 파라미터를 프로젝트 설정파일에서 정의하면 됩니다 :)
STEP 3. GPT model 을 교체하고 파라미터를 조정합니다.
저는 3.5에서 gpt-3.5-turbo-instruct 모델을 사용하기로 했습니다!
같은 프롬포트로 실행해보았을때 text-davinci-003 모델보다 좋은 성능의 답변을 보이면서 다른 모델들보다 Max token수도 부담 없었기 때문입니다.
모델 설명을 보신 후 본인의 프로젝트의 목적이나 사양에 맞는 모델을 선택하시면 됩니다!
또, 아까 테스트해봤던 대로 가장 적합했던 파라미터로 조정해줍니다!!
📝 저는 아래와 같이 설정하기로 했습니다. 📝
- model: gpt-3.5-turbo-instruct
- temperature: 1
- max tokens: 1920
- Maximum Length: 256
- Top P: 1
- frequency penalty: 0
- presence penalty: 0
정의 역시 서비스키와 max token수를 정의했던 설정파일에 동일하게 적용하시면 됩니다.
chatgpt.model: 원하는 모델명(ex.gpt-3.5-turbo)
[application.properties]
# OpenAI Service Key configuration
chatgpt.api-key=${GPT_KEY}
chatgpt.max-tokens: 1920
chatgpt.model: gpt-3.5-turbo-instruct
이후, APP을 실행하여 API 테스트를 해봤습니다.
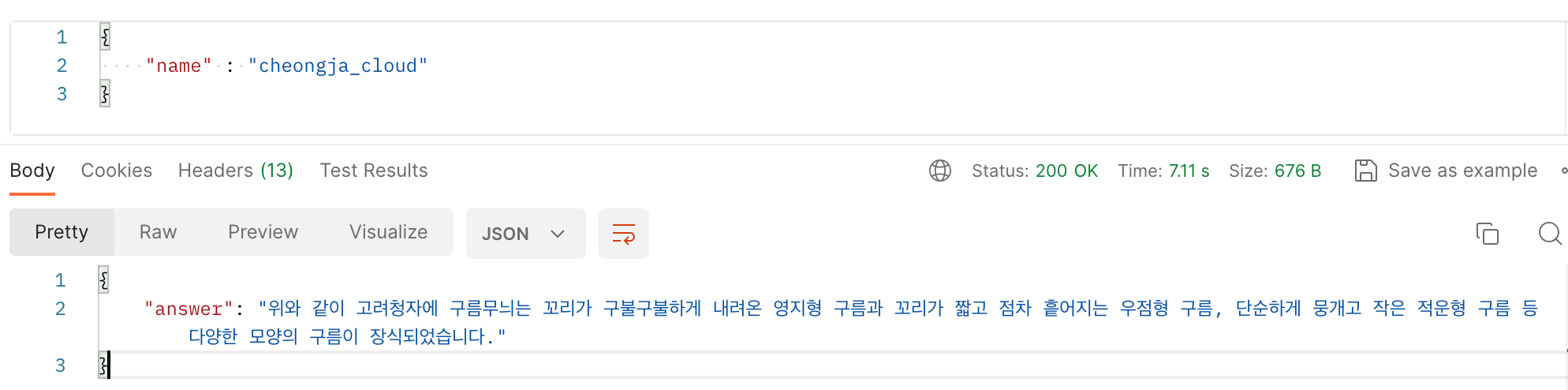
청자에서 구름 부분에 대한 해설을 잘 제공해주는 걸 확인할 수 있었습니다!!

[TIP] GPT API 사용시 주의할 점 🚨
여기까지 GPT 연동을 하신 여러분 수고 많았습니다!
이제 마지막으로 주의점을 알려드리고 마치겠습니다.
GPT API는 Rate Limit라는 속도 제한이 있습니다.
이 제한은 RPM (분당 요청), RPD (일일 요청), TPM (분당 토큰), TPD (일일 토큰), IPM (분당 이미지) 의 5가지 방식으로 측정됩니다!
- RPM (Requests per Minute):RPM은 GPT API에서 처리할 수 있는 요청의 수를 분 단위로 나타낸 것. 즉, 클라이언트가 GPT API로 보낼 수 있는 최대 요청 수를 나타냅니다.
- RPD (Requests per Day): API에서 처리할 수 있는 요청의 수를 일별로 나타낸 것
- TPM (Tokens per Minutes): API가 처리할 수 있는 토큰의 수를 분 단위로 나타낸 것
- IPM (Images per Minutes): API가 처리할 수 있는 이미지 수를 분 단위로 나타낸 것
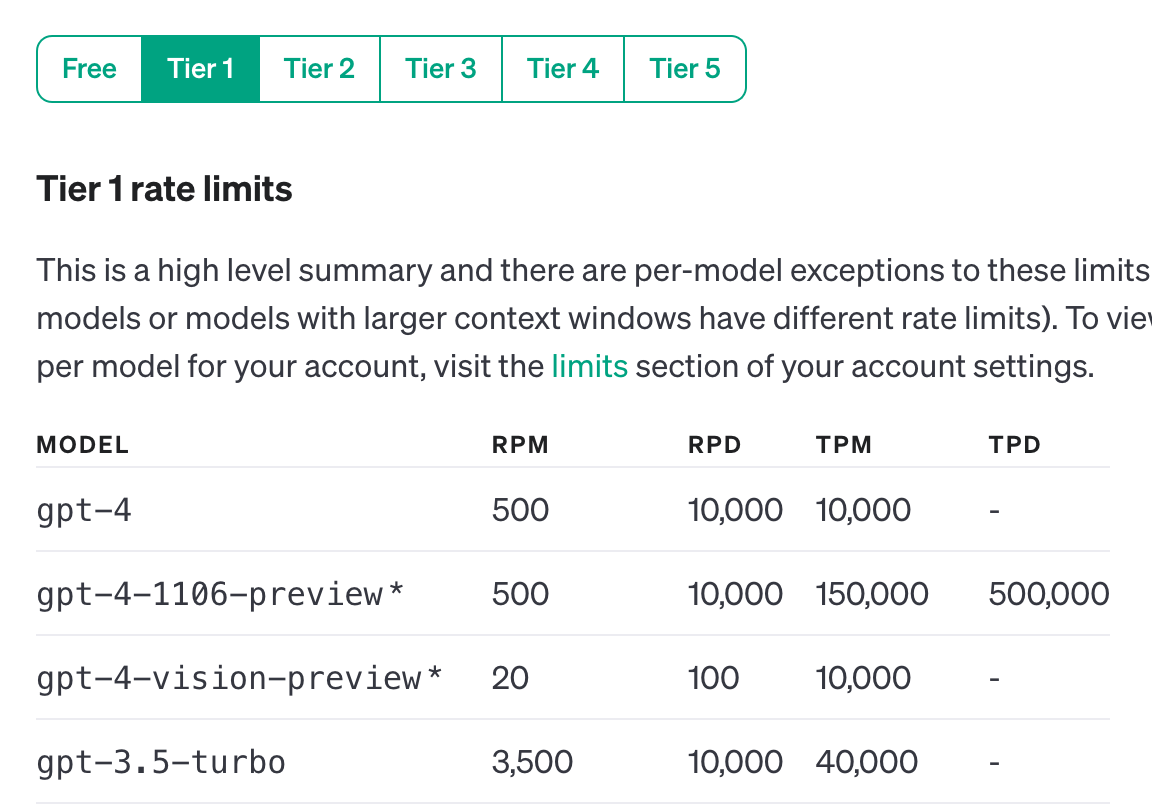
가장 많이 쓰는 모델인 gpt-3.5-turbo 기준으로 봐볼까요?
Free-tier 이용의 경우 분당 3회, 일당 200회, 분당 20,000개의 토큰이 제한량으로 정해져있네요!

여기서 가장 주의해야될 부분은 TPM 토큰 부분입니다. 길이가 동일하더라도 한글의 토큰 수가 영어보다 많이 필요합니다.
그래서 영어로 프롬포트를 작성하는 게 최선의 방법이긴 하지만 한글로 작성하더라도 토큰 수를 유의해서만 쓰시면 됩니다! (저도 한글로 쓰고 있습니다~)
openAPI에서 텍스트 토큰을 계산해볼 수 있게 하는 Tokenizer가 있습니다.
OpenAI Platform
Explore developer resources, tutorials, API docs, and dynamic examples to get the most out of OpenAI's platform.
platform.openai.com
동일한 글자수로 한글과 영어 토큰 수를 직접 비교해볼까요?
영어의 경우 7글자가 2토큰인데 한글은 7토큰입니다.
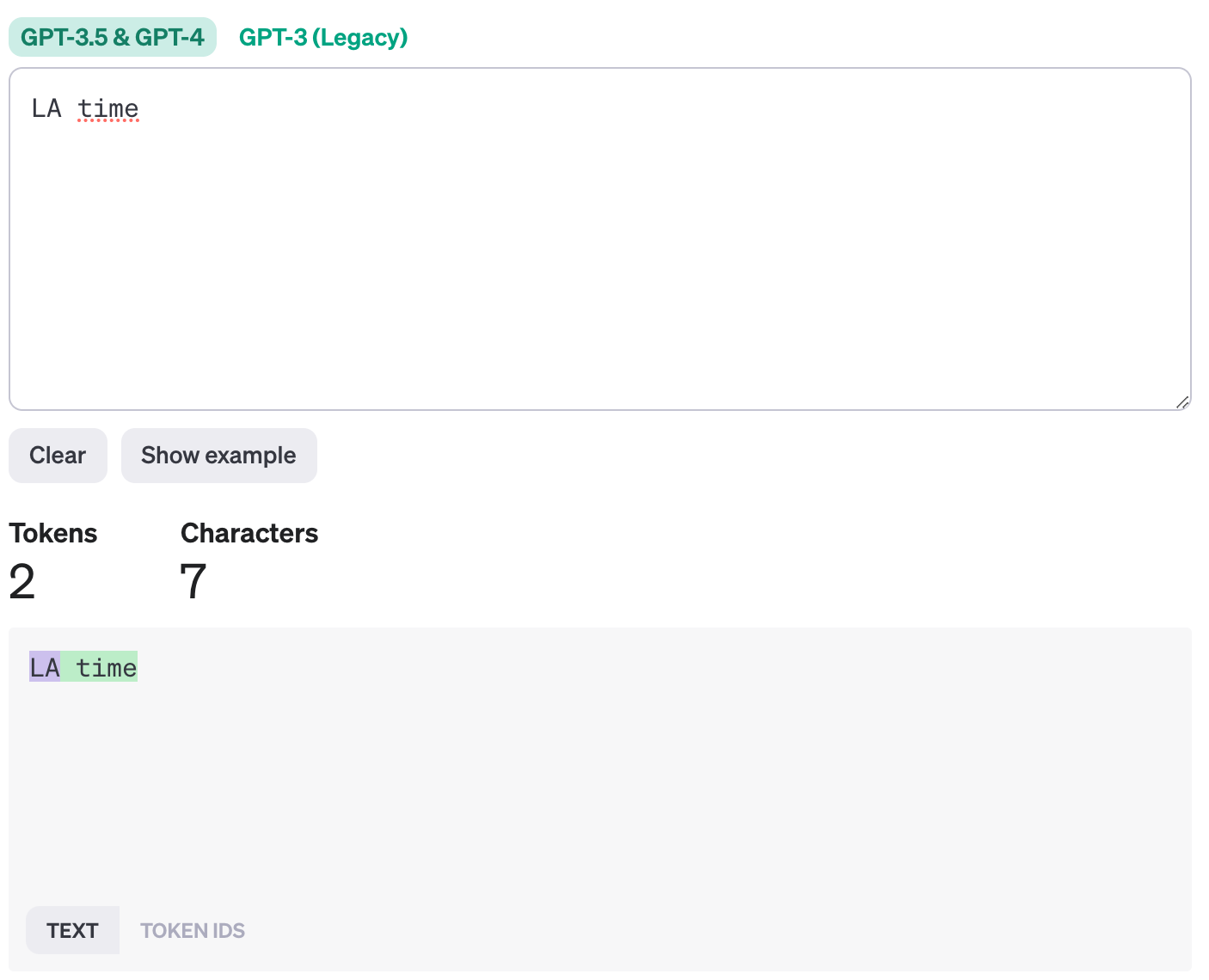
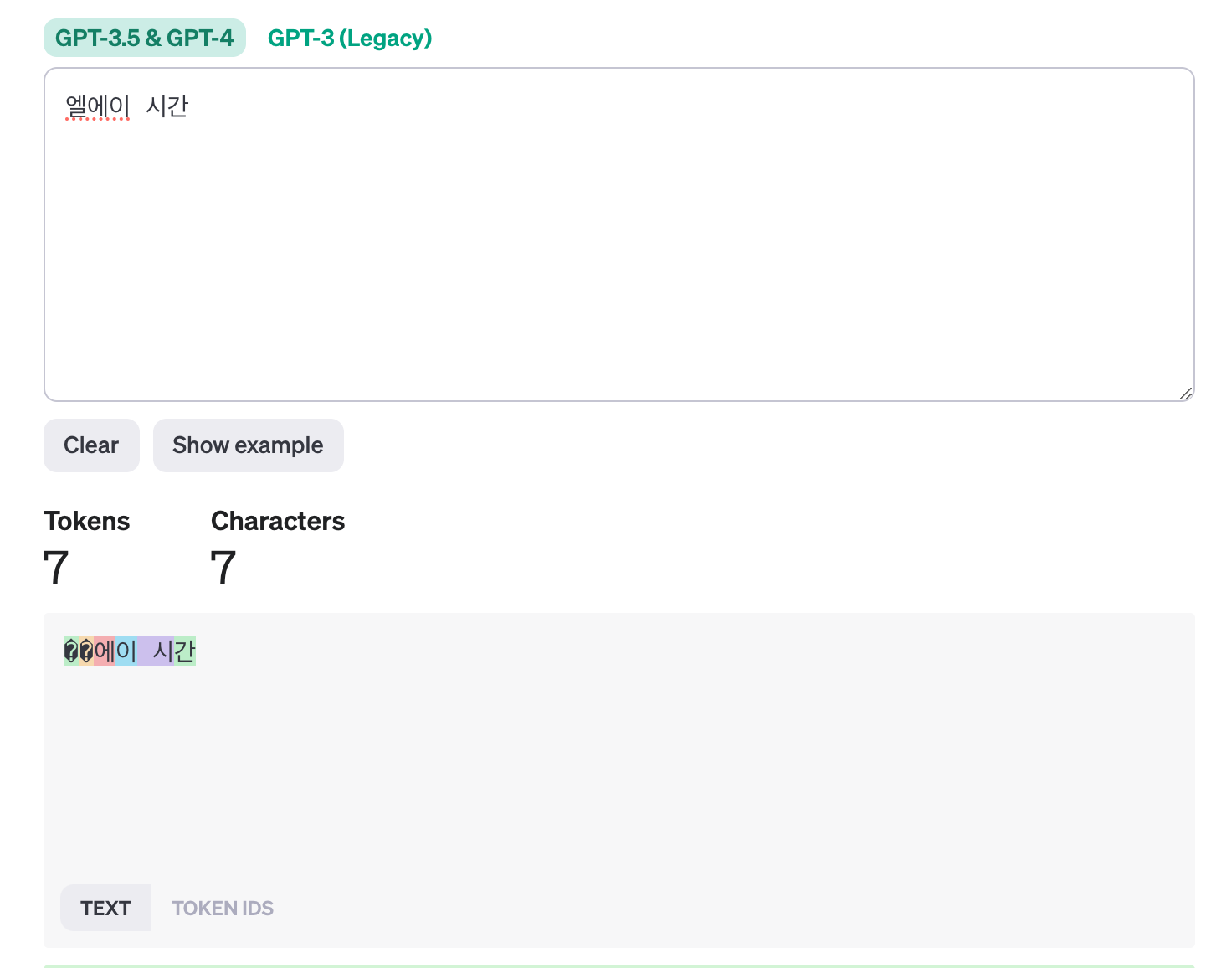
그래서 여러분께 권장드리고 싶은 방법은 1) 만약 한글 프롬포트를 꼭 사용해야하고 2) GPT의 기능이 중요한 프로젝트일 경우 openAI를 유료로 사용하는 것입니다. 왜냐하면 최소 유료 계정으로만 전환을 하더라도 넉넉하게~ 사용할 수 있기 때문입니다.
유료 계정의 minimum이 5달러이므로 5달러만 결제해놓고 GPT를 사용한다면 Tier 1에 속하게 되는데요.

Tier1만으로도 GPT를 매우 넉넉한 제한량으로 사용할 수 있습니다.
아까 gpt-3.5-turbo Free tier의 경우 3/200/20,000인게 기억 나시나요?
Tier1은 이에 비해 훨씬 넉넉한 제한량을 갖고 있는 걸 볼 수 있습니다!
여러분의 프로젝트 안정성과 확정성을 위해서 유료 계정으로 전환하는 것을 권장드립니다.
글 읽어주셔서 감사합니다~

참고
https://platform.openai.com/docs/models
'Graduation Project' 카테고리의 다른 글
| [YOLO] 데이터셋 생성부터 Colab으로 YOLOv5 학습까지 (ML 노베가 쉽게 알려드립니다) (1) | 2023.05.24 |
|---|