

이 글은 2023-1 졸업 프로젝트 개발 일지를 기록하는 첫번째 시리즈의 글입니다.
프로젝트에 대한 기본 소개를 먼저 한 후에 데이터셋을 구축하는 방법과 Google Colab을 통해 YOLO v5로 학습시키는 과정에 대해 소개하겠습니다!
0. 프로젝트 소개
프로젝트 명은 '외국인 관광객을 위한 한국미술 조각조각 뜯어보기 - 부분 해설 기반 미술관 도슨트 서비스'로,
외국인 관광객들에게 국립 중앙 박물관 내의 주요 작품들에 대한 해설을 '부분'으로 '인터렉티브'하게 제공하는 것이 목표입니다!
🖼
쉽게 예를 들어 유저 관점으로 설명드려보겠습니다.
국립중앙박물관에 방문한 관광객 A씨는 김홍도의 <서당>이라는 작품에 관심이 궁금합니다. 🤔
- A씨는 어플에 접속해 <서당>의 사진을 찍어 그림을 인식📷 시킵니다.
- 어플은 <서당> 해설의 소제목들을 보여줍니다. (예. 1. 혼나는 아이 2. 혼내는 훈장님...) A씨는 훈장님이 가장 궁금해 2번을 선택했습니다.
- A씨가 2번 소제목에 해당하는 그림의 부분🧩 (즉, 훈장님)을 카메라로 찍으면 2번에 관한 해설이 제공됩니다!
- 이런 식으로 그림의 모든 소제목의 해설들을 Unlock🔓하면.. 그림에 대한 뱃지를 업적🏆으로 얻을 수 있게 되고, 나의 도감📜 에 저장됩니다.
- 이렇게, 서당이라는 그림을 퀘스트를 완수하듯 재미있게 감상한 A씨는 이제 다음 그림으로 넘어갑니다 :)
#개발 배경
저희 팀은 해외 미술관에서 겪은 공통 경험을 통해 이 프로젝트를 시작하게 됐습니다.
- 도슨트는 시간적으로 비용적으로 부담이 된다.
- 해설기기는 일방향적인 소통의 문제가 큼: 궁금한 부분에 대한 설명까지 기다려야 하고 그 부분에 대한 설명이 언제 나올지도 알 수 없다. 게다가, 전체 소요시간이 부담된다.
이러한 문제점을 바탕으로, 저희는 인터랙션 가능한 해설을 제공하고,
한국 미술관에 이를 도입해 한국 미술 홍보효과까지 기대해보고자 합니다!
#주요 기능
현재까지 생각해본 주요 기능은 다음과 같습니다.
- 카메라 촬영으로 작품 인식
- 모바일 기기 화면에 작품 출력
- 작품의 해설을 부분별로 나누어 텍스트와 오디오로 제공
- 작품의 모든 부분들을 모으면 전체 해설 제공
#구현 계획
구상 중인 주요 기술 스택은 다음과 같습니다.
- ML: YOLO v5 Object Detection + tflite
- Front-End: Flutter
- Back-End: Spring Boot
자, 그럼 여기까지가 매우 간단한 프로젝트 소개였고 이제 본격적으로 들어가봅시다.
이번 포스팅에서는
1) 그림 데이터셋 만들기
2) YOLO v5로 내가 만든 데이터셋 학습시키기
2) 그림에서 bounding box와 함께 object를 detection하는 것
을 해볼 것입니다!
쉽게 알려드릴 예정이니 천천히 따라와주세요~!
노베인 저도 했으니 여러분도 충분히 할 수 있습니다. 🔥

1. 데이터셋 생성
자.. 먼저 학습을 시키든 object detection을 하든 하려면 데이터셋이 있어야겠죠?
어떻게 만드냐구요? 매우 간단합니다. (사실 전 몰라서 몇주를 찾았지만😂ㅋ)
아래 Roboflow라는 사이트를 통해 기본으로 제공하는 데이터셋을 다운로드 받을 수도 있고 데이터셋을 직접 만들 수 있습니다.
일단 접속 후 가입해주세요.
Roboflow: Give your software the power to see objects in images and video
With just a few dozen example images, you can train a working, state-of-the-art computer vision model in less than 24 hours.
roboflow.com
Project 탭에서 Workspaces를 생성하고 [+ Create New Project]를 눌러 새 프로젝트를 생성해주세요!

이제 프로젝트가 생성됐으니 좌측의 'Annotate'를 클릭해주세요.
🌱 ML 노베를 위한 설명 🌱
Annotate란? 데이터셋에 메타데이터를 추가하는 것.
쉽게 말하면 AI가 데이터의 내용을 이해하도록 주석을 달아주는 작업입니다!
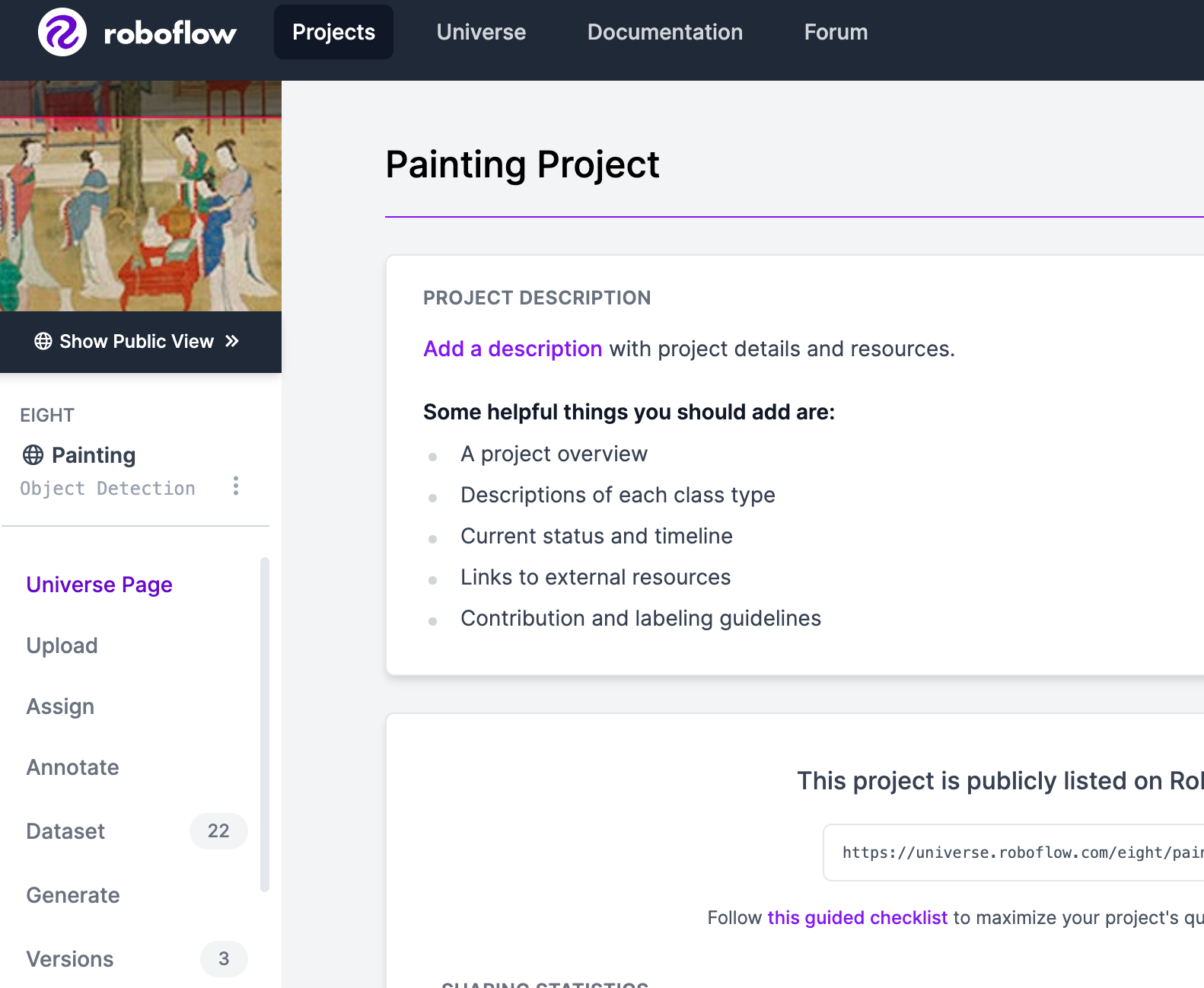
[Upload More Images] 클릭! 이제 이미지를 업로드하며 Bounding Box를 만들어주는 작업을 거칠 것입니다!
⭐ (TIP)! ⭐
시간 절약을 위해 여러장의 이미지를 불러와 이 작업을 거치고 한꺼번에 batch하는 걸 추천드려요!
🌱 ML 노베를 위한 설명 🌱
Bounding Box 란? 이미지 내에서 물체의 위치를
사각형으로 감싼 형태의 도형으로 정의하고 꼭짓점의 좌표로 표현하는 방식
저는 <권대운 기로연회도> 이미지를 업로드해 'men', 'women' 영역의 bounding box를 만들어주었습니다!
여러분이 detection을 원하는 부분을 사각형 툴로 그리고 라벨링을 해주면 되는 것이죠.

작업이 끝났다면 [Save and Continue] 누르면 이런 식으로 어디에 이 이미지를 넣어? 라는 창이 뜹니다.
Training set으로 써야하니 다음과 같이 선택해주면 되죠.
🌱 ML 노베를 위한 설명 🌱
Training Set란? 이름 그대로 학습을 위해 사용되는 데이터입니다.

이런 식으로 이미지를 업로드해서 Training set을 만들어주면 되는 겁니다!
그럼 이제 이 dataset을 다운받아야 겠죠?
좌측의 'Generate'를 클릭해주세요!
그러면 아래 이미지와 같이 Dataset을 원하는 형식으로 generate할 수 있는 화면이 나옵니다.
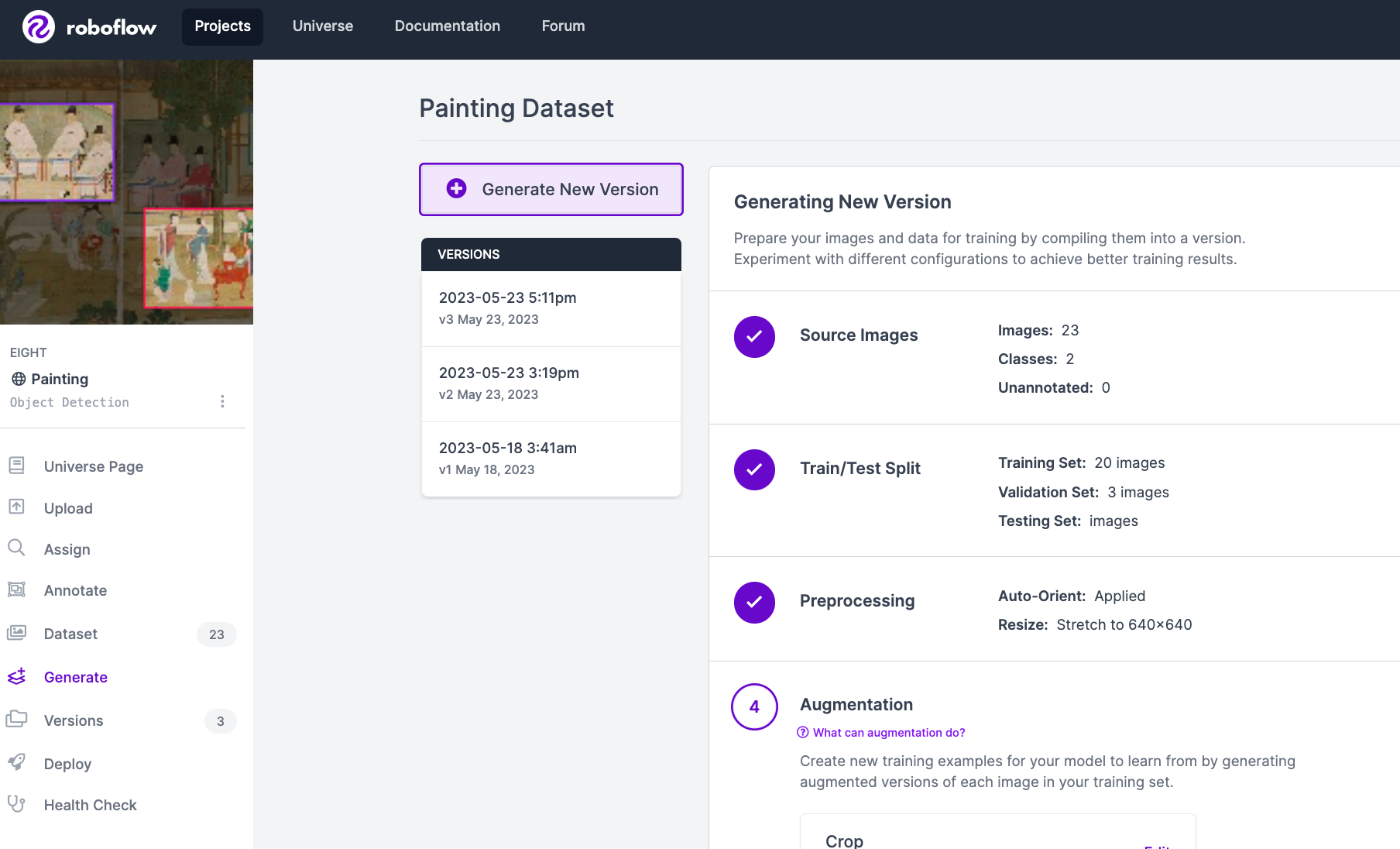
⭐ (TIP) 여기서 중요한 것! ⭐
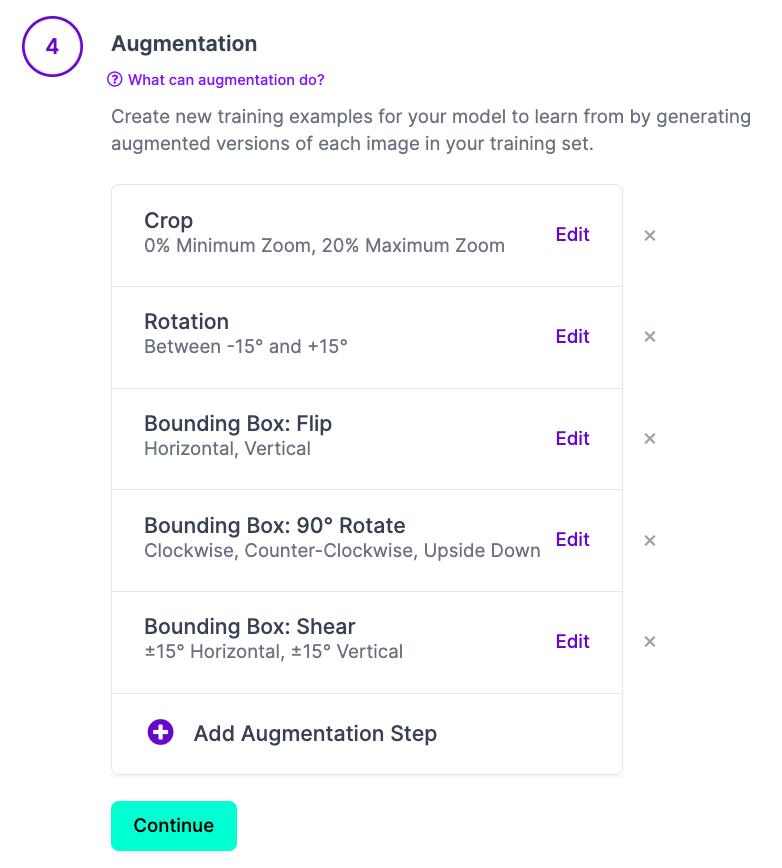
Augmentation에서 아래 요소들만을 추가하는 것을 추천드립니다.
여러 증강 옵션을 넣어서 총 이미지 개수를 더 늘려주는 겁니다.
제가 추가한 요소들을 간단히 설명드리자면 사진을 크롭도 하고 회전도 시키고 상하좌우 반전도 시키며 데이터양을 늘리도록 했습니다.
너무 많이 선택하면 YOLO 학습이 잘 되지 않을 수 있습니다. #과유불급 ..

generate가 끝나면 이제 원하는 형식의 데이터셋을 다운받을 수 있는데요.
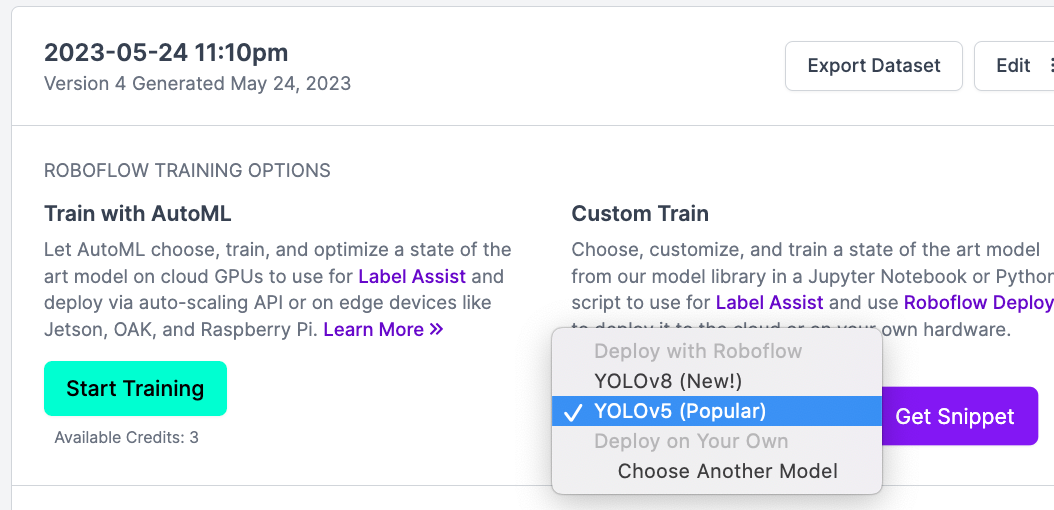
저희는 YOLOv5에 사용할 예정이니 YOLO를 선택해주시면 됩니다. 😉
YOLOv5 (Popular)로 [Get snippet] 클릭 -> Terminal 탭에 있는 다운로드 코드를 복사해주세요!
Colab에서 이 코드를 통해 방금 만든 데이터셋을 다운로드 받아줄 예정입니다.
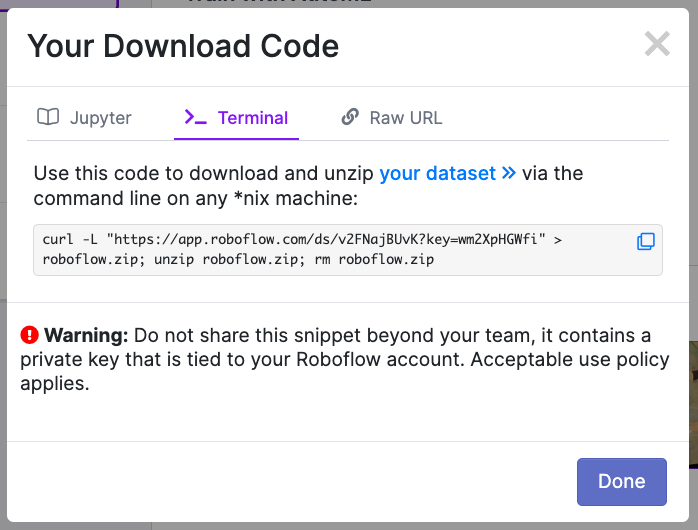
자 여기까지 했는데? 벌써 데이터셋을 생성했습니다!!! 👏👏🏼👏🏽👏🏾
이제 YOLO를 사용하러 가봅시다!

2. Colab으로 YOLO v5 학습시키기
Google Colab 이란?
Colab은 구글에서 만든 연구용 서비스 제품이며, Jupyter를 기반으로 만들어진 웹용 서비스입니다!
Cloud service를 통해 Jupyter에서 작업을 해야 하는 Machine learning을 Colab을 통해 손쉽게 돌릴 수 있습니다.
시작하기 전에, YOLO의 기본 원리가 궁금하신 분은 제 블로그의 해당 포스팅을 참고해주세요 :)
[YOLO] YOLO(You Only Look Once)란?
YOLO 개념 You Only Look Once의 약자로 Object detection 분야에서 많이 알려짐 하나의 이미지 데이터를 여러개의 이미지 데이터로 나누어 분석하는 것이 아닌 전체의 이미지를 이용해 학습하고 예측함 YOL
dev-yeni.tistory.com
0) Goolge Colab 환경 세팅
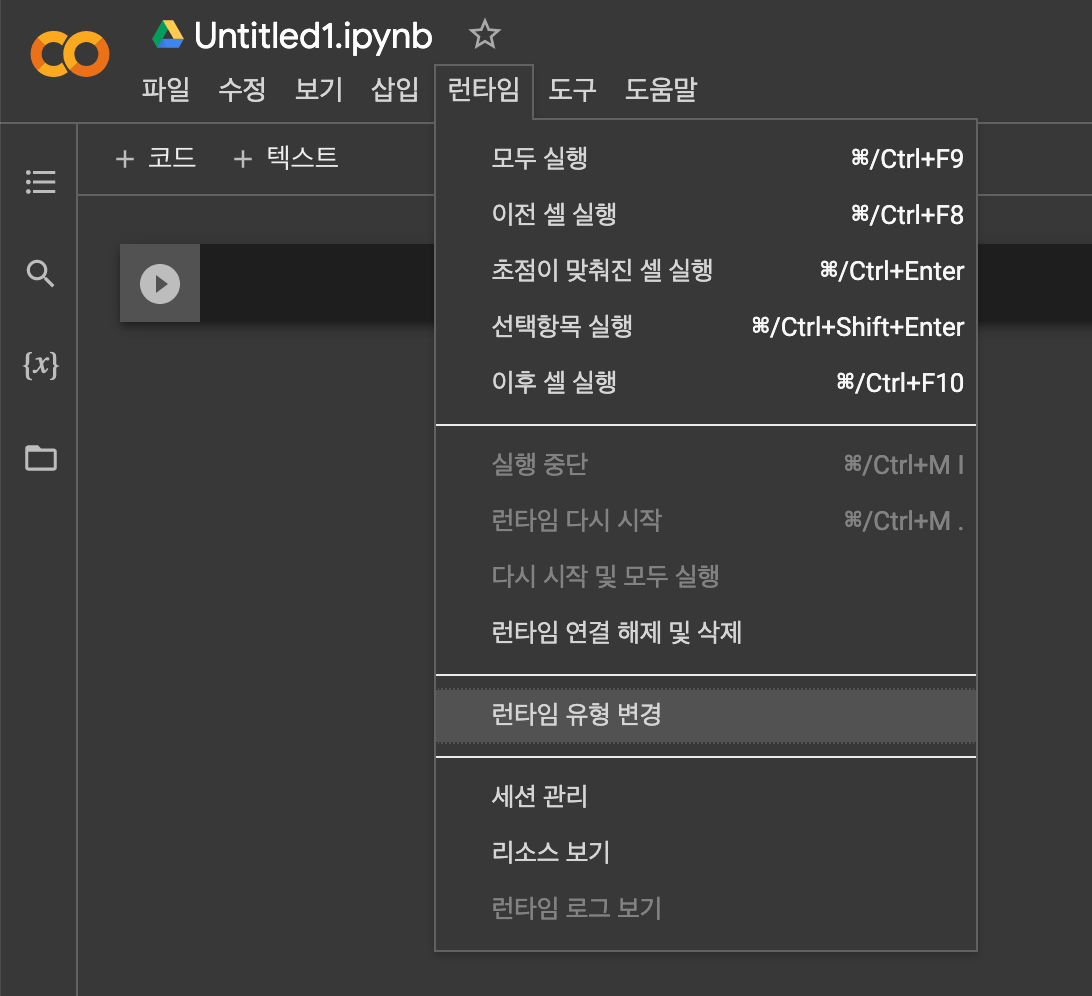
구글 드라이브에 접속해 새로 만들기 > 더보기 > Google Colaboratory 를 선택합니다.

생성된 파일에 접속해 런타임 > 런타임 유형 변경을 선택해 하드웨어 가속기를 GPU로 변경해주고 [저장]을 누릅니다.
🌱 ML 노베를 위한 설명 🌱
왜 GPU를 쓰나요? 딥러닝 환경에서 가장 중요한 것은 GPU입니다. (CPU만 있어도 딥러닝 알고리즘을 실행할 수는 있지만 연산속도가... 😰)
GPU는 성능 향상과 빠른 속도를 자랑합니다.
이런비싸고좋은 장비를 구매하지 않고 Colab에서 무료로 사용할 수 있으니 굉장히 좋은 것 같습니다.
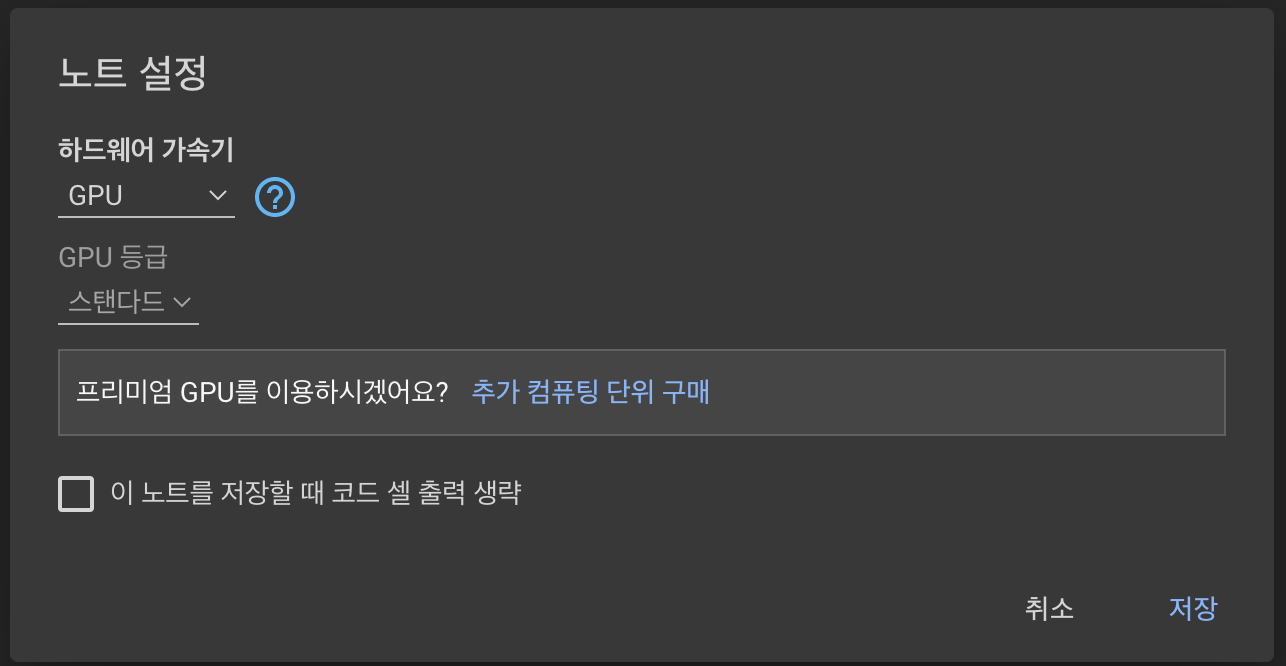
그럼 이제 GPU를 사용하는 환경이 세팅이 된 것입니다! (나도 있어 GPU)
1) Dataset 가져오기
아까 복사했던 다운로드 코드를 이용해 생성한 데이터셋을 colab에 다운로드 받아줍니다!
!curl -L "https://app.roboflow.com/ds/RBKFsgSvtr?key=RraxvhyXoc" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
dataset 이라는 이름으로 새 폴더를 생성해 생성되었던 방금 다운로드로 받아온 모든 파일을 넣어줍니다. (아래 그림 참조)
2) YOLO v5 환경 세팅
생성한 나의 Google Colab에 YOLO v5를 다운로드해주어야만 YOLO v5를 쓸 수 있습니다. git clone을 해와서 설치합니다.
%cd /content
!git clone https://github.com/ultralytics/yolov5.git설치가 완료되면 YOLOv5을 위한 패키지를 설치합니다.
%cd /content/yolov5/
!pip install -r requirements.txtcontent/yolov5 폴더가 생성되어있을 겁니다!
3) data.yaml 경로 재설정 및 train, valid set 나누기
🌱 ML 노베를 위한 설명 🌱
data.yaml 이란? 데이터 표현 양식의 한 종류입니다.
데이터는 다양한 포맷으로 표현될 수 있는데 우리가 일반적으로 사용하는 JSON이나 XML도 표현 양식입니다. yaml 기본 구조는 key-value 형식으로 작성되어 있습니다!
data.yaml이 무엇을 포함하고 있는지 확인해보겠습니다.
아래 코드를 실행하면 train 경로와 valid 경로가 잘못 설정되어 있는 것을 확인할 수 있습니다. 경로 변경을 곧 해주겠습니다.
미리 말씀드리자면, 이미지의 경로들을 txt파일로 모아준 뒤에 경로 재설정을 해줄 것입니다!
%cat /content/dataset/data.yaml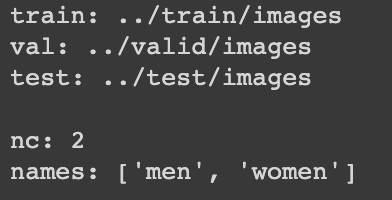
먼저 route로 이동하고 glob이라는 패키지를 이용합니다. dataset/export 파일 안에 있는 모든 이미지들을 list로 만들어줍니다.
list안에 이미지가 몇개가 있는지 확인도 합니다.
%cd /
from glob import glob
img_list = glob('/content/dataset/export/images/*.jpg')
print(len(img_list))
img_list를 train set과 valid set으로 나눠줍니다!
이것도 마찬가지로 각가의 list안에 이미지가 몇개가 있는지 확인해봅시다.
🌱 ML 노베를 위한 설명 🌱
train set란? 모델을 학습하기 위한 데이터셋
valid set란? 학습이 이미 완료된, 검증을 위한 데이터셋
차이를 확실히 아시겠죠?
from sklearn.model_selection import train_test_split
train_img_list, val_img_list = train_test_split(img_list, test_size = 0.2, random_state = 2000)
print(len(train_img_list), len(val_img_list))
이제, train 이미지 경로와 valid 이미지 경로를 txt 파일로 저장합니다!
그러면 dataset 폴더에 train.txt와 val.txt가 생깁니다.
with open('/content/dataset/train.txt', 'w') as f:
f.write('\n'.join(train_img_list) + '\n')
with open('/content/dataset/val.txt', 'w') as f:
f.write('\n'.join(valid_img_list) + '\n')
train과 valid의 경로를 재설정해줍니다.
import yaml
with open('/content/dataset/data.yaml', 'r') as f:
data = yaml.safe_load(f)
print(data)
data['train'] = '/content/dataset/train.txt'
data['val'] = '/content/dataset/val.txt'
with open('/content/dataset/data.yaml', 'w') as f:
yaml.dump(data, f)
print(data)
경로가 정상적으로 바뀌었음을 확인할 수 있습니다!!
4) YOLOv5 학습
대망의 학습시간입니다! (두둥)

train.py를 실행시켜 YOLOv5를 학습시켜 줍니다.
(roboflow에 있는 샘플 데이터셋을 이용하면 약 30분 정도 소요됩니다. 제가 생성한 데이터셋은 크기가 작아서 금방 됐습니다.)
아래 명령어의 용어들이 생소하실 분이 있을 것 같아 간단히 말씀드리겠습니다!
이미지, 배치, epoch의 크기를 지정해준 것이고 cfg는 모델의 크기를 뜻하는데 이는 yolov5s.yaml에 저장되어 있기 때문에 이를 경로로 지정해줬습니다! weights 또한 yolov5s.pt에 저장되어 있기 때문에 경로를 지정해준 것이죠.
%cd /content/yolov5/
!python train.py --img 416 --batch 16 --epochs 50 --data /content/dataset/data.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt --name results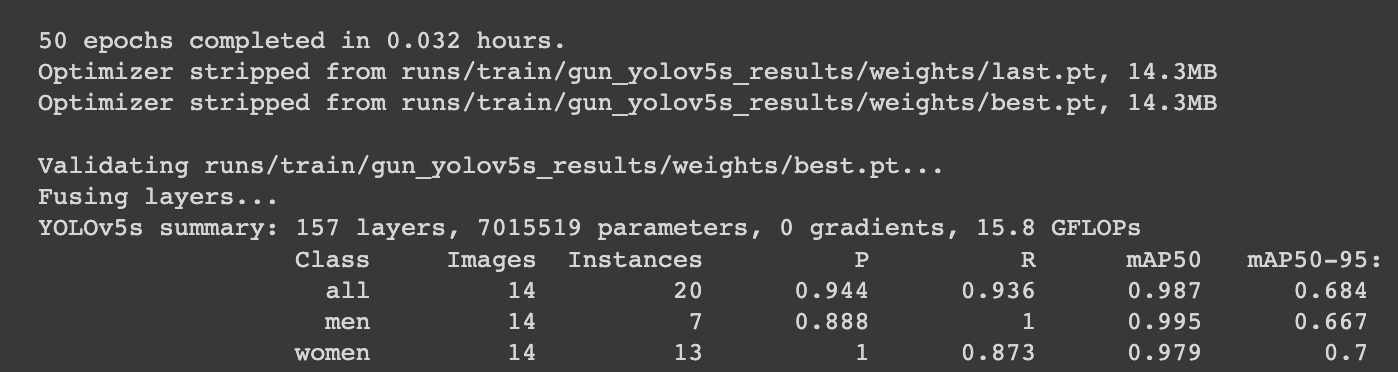
성공적으로 학습이 끝나면 다음과 같은 결과를 볼 수 있습니다! best.pt파일이 생긴 디렉토리도 알려주네요.
(옵션) tensorboard로 학습 결과를 상세하게 확인해볼 수도 있습니다! 궁금하신 분들은 해보셔도 좋고 아닌 분들은 생략해도 됩니다.
%load_ext tensorboard
%tensorboard --logdir /content/yolov5/runs/
5) 테스트 데이터로 추론하기
드디어.. 학습도 끝났고 이제 잘 object detection을 하는지 테스트해봅시다!
물체를 인식하기 위해서 사진이나 동영상이 필요한데
직접 업로드를 해도 되고 테스트 데이터를 이용해 인식시켜보아도 됩니다!
저는 기존에 있던 데이터로 인식을 시켜보았습니다.
맨 아래 명령어에서 디렉토리는 본인의 디렉토리에 맞게 변경해 작성해주시면 됩니다! 그리고 편의를 위해 바로 이미지 결과를 보여주도록 했습니다.
from IPython.display import Image
import os
val_img_path = val_img_list[1]
!python detect.py --weights /content/yolov5/runs/train/gun_yolov5s_results/weights/best.pt --img 416 --conf 0.5 --source "{val_img_path}"
Image(os.path.join('/content/yolov5/runs/detect/exp5', os.path.basename(val_img_path)))
결과는................
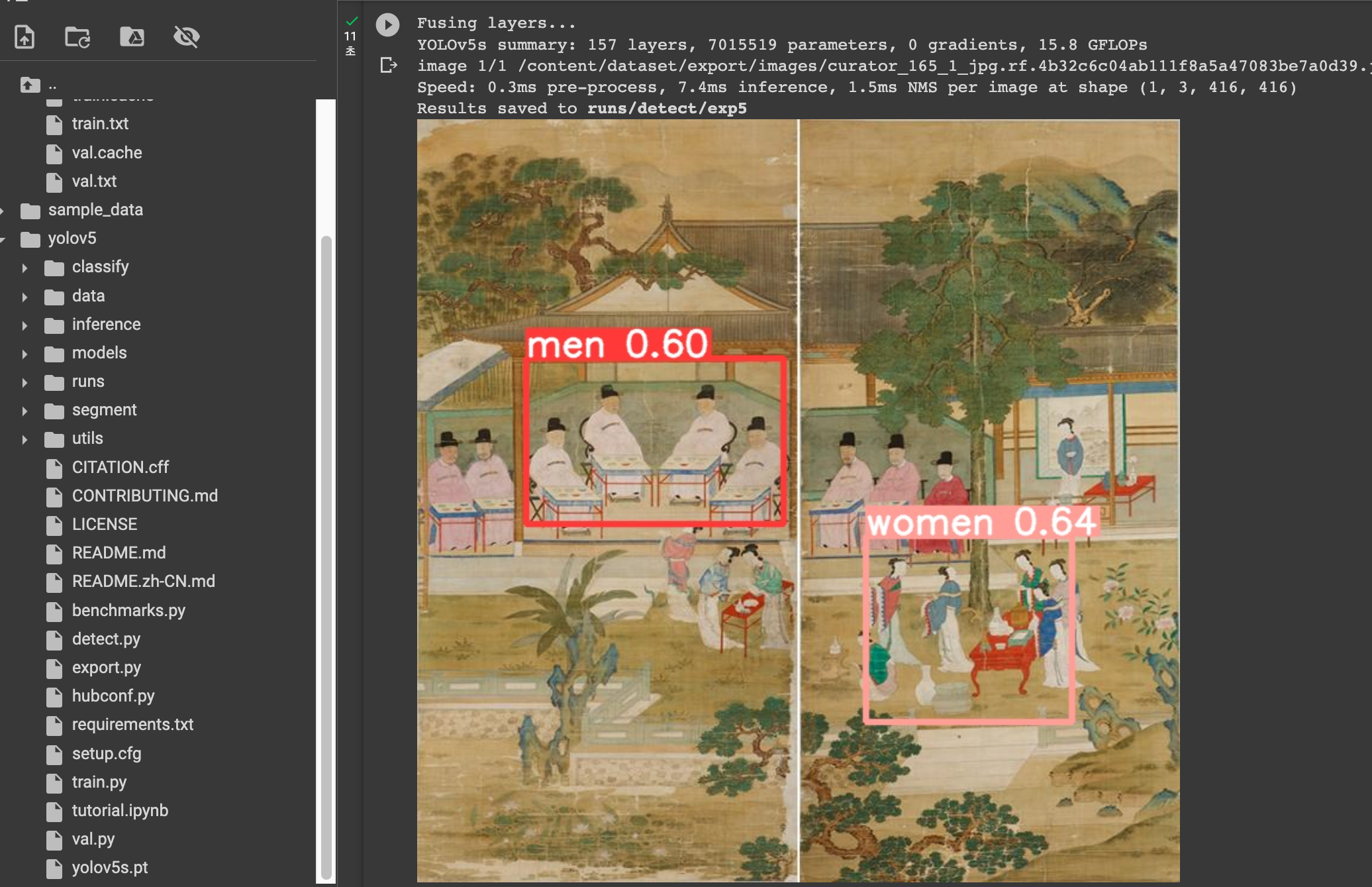
다음과 같이 men, women을 잘 인식하는 것을 확인해볼 수 있었습니다!!! (감격)

오늘의 포스팅은 여기까지입니다!
하시면서 어려운 점이나 궁금한 점이 있다면 언제든지 댓글로 남겨주세요~~!
그럼 다음 포스팅에서 뵙겠습니다.
제 프로젝트도, 이걸 보는 여러분들의 프로젝트도 성공적으로 끝나길 바라며 화이팅입니다!

참고자료
1) https://www.youtube.com/watch?v=T0DO1C8uYP8
2) https://velog.io/@jnine/YAML%EC%9D%B4%EB%9E%80
3) https://cordingdiary.tistory.com/86
4) https://velog.io/@cha-suyeon/딥러닝-Object-Detection-개념과-용어-정리
'Graduation Project' 카테고리의 다른 글
| [GPT] Spring 환경에 GPT API 연동하여 서비스 구현하기 (0) | 2023.11.14 |
|---|